On the request of prof. dr. Koenraad Verboven, GhentCDH created the web application https://gdrg.ugent.be/. In this application, part of the data of the Ghent Database of Roman Guilds and Occupation-Based Communities (GDRG) is made publicly available.
GDDRG Home page
About GDRG
GDRG has two proximate aims:
- To provide a heuristic device allowing scholars to find information on non-family collectives based on shared profession, ranging from informal communities (for instance foreign mercantile communities such as the cives Romani qui negotiantur) to highly formalised associations (for instance the corpora naviculariorum assisting/working for the annona).
- To provide an analytical tool allowing scholars to study relations between the characteristics (attributes) of these collectives; for instance to study the relation between patronage over collegia by persons from the imperial elite, location and assets controlled by occupational groups. Some of these analyses can be done using the online version, but the data can also be downloaded in CSV format and the researchers are happy to provide also the raw data in access.
The ultimate aim of the designer of the GDRG (prof. dr. Koenraad Verboven) is to study institutions and resources for collective action available to these groups to coordinate cooperation, ranging from social norms (informal institutions) and relations (social capital) to formal statutes (the leges collegiorum) and material assets.
The research team behind the GDRG consisted of Prof. dr. Koenraad Verboven (project director), Luka Tjampens (data input and control), and Gerben Verbrugghe (GIS).
Acknowledgements
Acknowledgments are due to:
- Pleiades.org, from where the CSV files with geographic information were downloaded. (Erroneous co-ordinates were corrected where necessary. Places not in the Pleiades CSV files were added.)
- Ancient World Mapping Centre, which provided us with the basemap and shapefiles of provincial boundaries, roads and rivers. (here too: the shapefiles were corrected where necessary).
Approach
Both the goals and solutions described below are the result of discussions between researchers and developers that started well ahead of the actual implementation phase. During the implementation phase, the developers tried to show the latest progress as soon as possible to the researchers, which resulted in early feedback and a lot of opportunities for additional questions in both directions. This open communication has proven to be a major help and contributed to a pleasant working environment.
Goals and challenges
The data of the Ghent Database of Roman Guilds and Occupation-Based Communities reside in a Microsoft Access database. The goal of the web application is to open up these data to other researchers and the broader public. In order to make this data even more useful to the public, some considerations were made:
- It should be easy to start exploring the dataset.
- The spatial and temporal information need to have a visual representation.
- It should be possible to export (parts of) the datasets to enable further processing.
Because the researchers already have an established editing workflow, the decision was made to keep the existing Microsoft Access database as an editing platform and to enable the data to be exported into the web application.
Solutions
Easy dataset exploration
Faceted navigation
A search interface with faceted navigation is provided to facilitate data exploration by the broader public. A separate search page had been provided for each of the main object types (Guilds, Guild documents and Persons), allowing for object type specific facets to navigate with. This gives a complete overview of the available data to start with, and makes it easy to filter these data using the available facets.
Elasticsearch is used to easily enable faceted navigation and the front end framework Vue.js is used to provide a better user experience.
Each of the resulting rows consist of the basic information related to a single object and contains a link to a page containing more detailed information on this specific object.
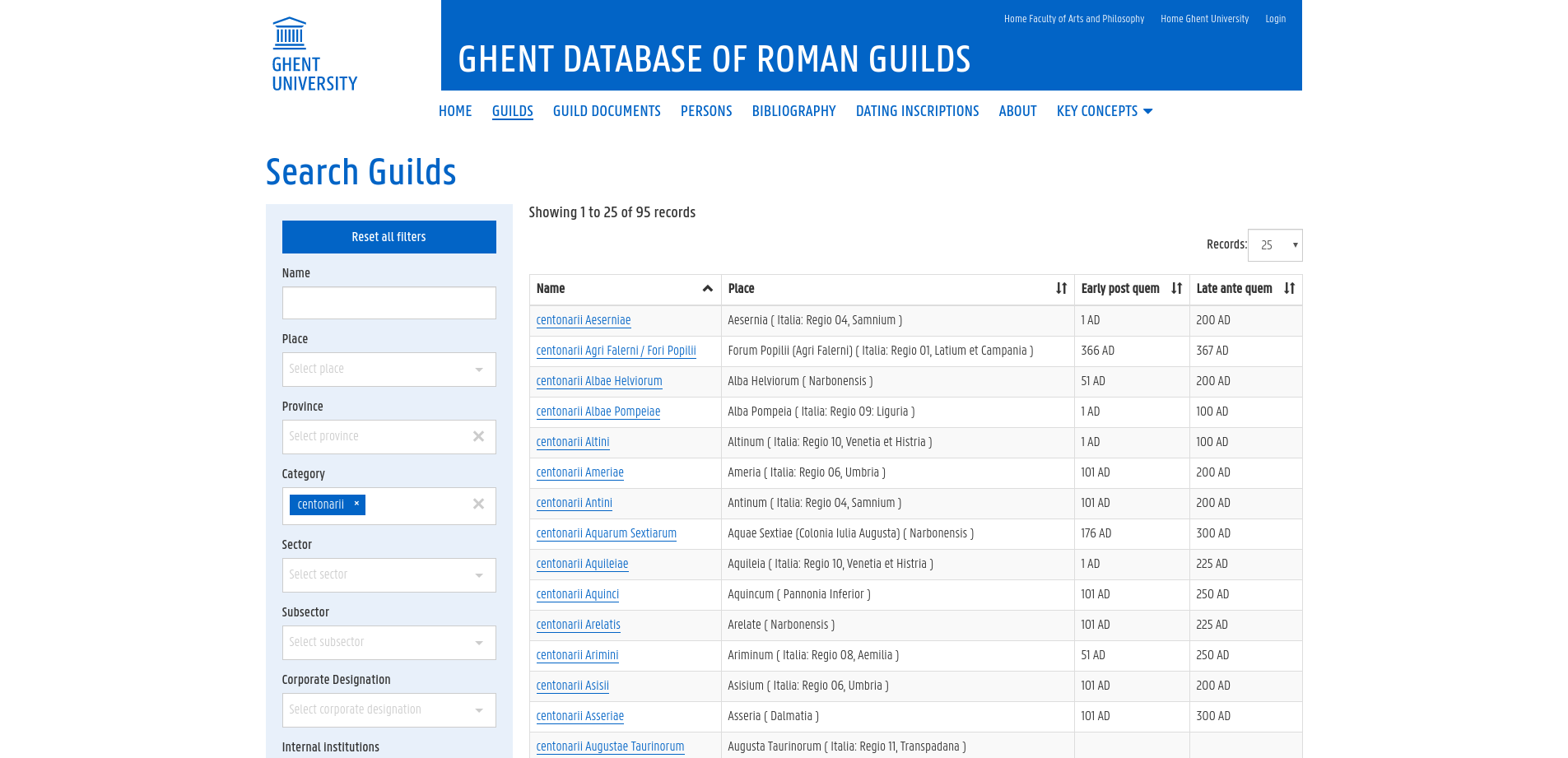 Search query: Guilds of category centonarii
Search query: Guilds of category centonarii
Related data objects
Next to the faceted navigation on the search pages, data exploration has also been taken into consideration on the detail pages of individual data objects. On these pages, other objects that are related to the current object are listed in a dedicated right column together with links to external datasets and works of reference where more information about the object at hand can be found.

Visualization of related data object for Guild Document "fabri Apuli municipii Septimii CIL 03, 01082"
Visualization of spatial and temporal information
Spatial visualization
A map has been provided on the search pages of the object types that contain geo information (guilds and guild documents). On these maps, all the objects that meet the criteria imposed by the current search query are indicated by a marker. The base map for these spatial visualizations has been created by the Ancient World Mapping Center and hosted on Mapbox. The borders of the Roman provinces and Regiones Italiae are based on boundaries published by the Ancient World Mapping Center, which were corrected by prof. dr. Koenraad Verboven and are hosted on a GeoServer.
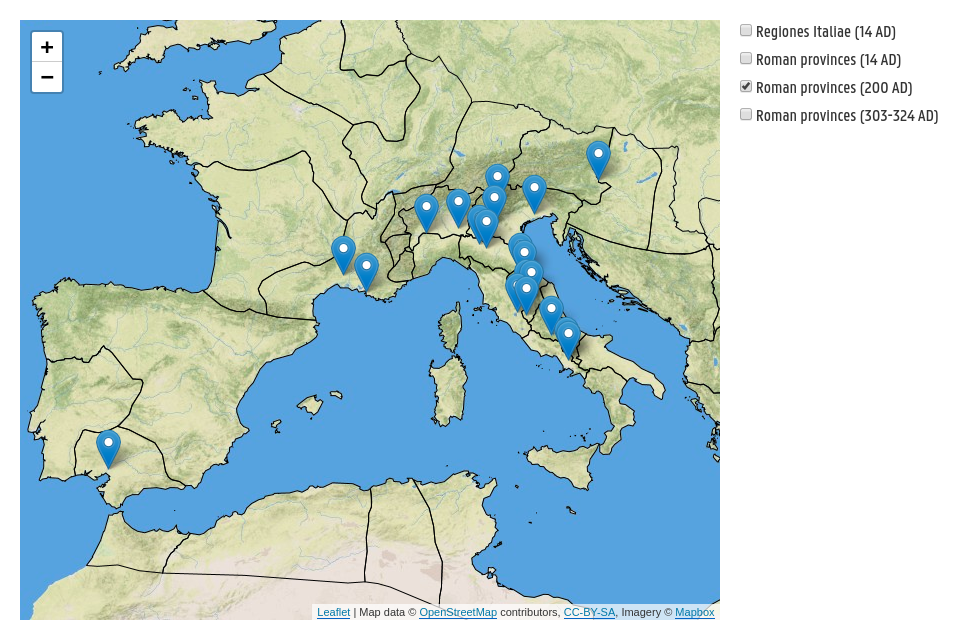
Search query: Guilds of category centonarii after 80 AD and before 215 AD
Temporal visualization
For the visualization of the temporal information, a pragmatic time distribution model has been developed starting from the ideas of prof. dr. Koenraad Verboven. The distribution model makes use of 25 year intervals and each object gets a weight for each of these intervals, based on its existence in this interval.
Let’s take a look at an example to clarify this model. The guild Fabri Tignuarii Praenestae existed from 7 / 3 BC until 101 / 138 AD. For the construction of the distribution, the outer dates are always used. The total time of existence is 145 years. In the interval 25 BC - 1 BC this results in a weight of 7/145. The intervals 1 AD - 25 AD, 26 AD - 50 AD, 51 AD - 75 AD, 76 AD - 100 AD and 101 AD - 125 AD get a corresponding weight of 25/145. For the last interval, 126 AD - 150 AD, the resulting weight is 13/145.
On the search page, the weights of all objects meeting the search query criteria are summed to obtain the total temporal distribution.
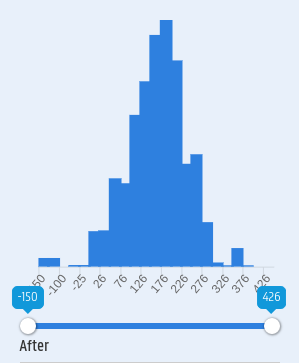
Search query: Guilds of category centonarii
Data export
On every search page, an “Export results to CSV” button is available to export detailed information on the data objects matching the search query into a CSV file. Researchers can then use this exported data to further process and analyze specific subsets of the dataset.
Getting the data out of Microsoft Access
Getting the data out of Microsoft Access proved to be a bigger challenge than anticipated. Microsoft Access is proprietary software and stores its data in a proprietary format. Different approaches were tried:
- Reading from PHP using an ODBC driver (provided by libmdbodbc1). This didn’t work for us.
- Writing from Microsoft Access to a MariaDB database. This did work, but only with 32-bit ODBC connectors (tested with version 5.3.11 and 5.3.12). After installation, an ODBC Data Source needs to be added for the connection with the MariaDB database. The 32 bit (vcredist_x86.exe) Visual C++ Redistributable Packages for Visual Studio 2013 are also required. Then a Visual Basic script to export all Access tables can be executed.
Global technical overview
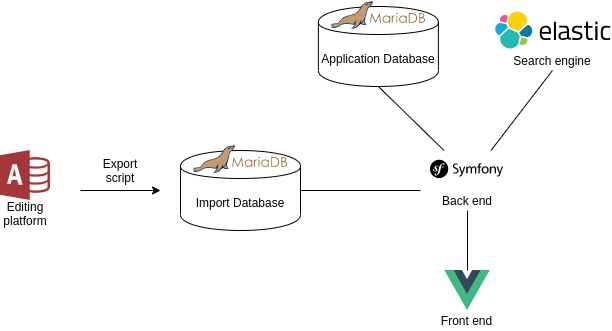
Data import
In a first phase, a researcher exports the dataset from the Microsoft Access editing platform to an import database (MariaDB) using an export script. When this export step is complete, the researcher can initiate the second phase in the web application. In this second phase, the data are first filtered (not all data present in the editing platform is ready for publication) in the import database. After filtering, the new data are indexed in new Elasticsearch indexes. When this indexing operation is finished, the tables from the application database are replaced by the tables from the import database and the old Elasticsearch indexes are replaced by the new ones.
Data consumption
All web pages in the GDRG web application are generated by the Symfony back end.
When a search page is consulted, the back end first requests the necessary raw data from Elasticsearch, after which an HTML page is rendered in which the Vuejs front end is included.
When a detail page is consulted, the back end obtains the required raw data from the application database and renders an HTML page with the processed data included.
Future work
The GhentCDH, as a member of the Clariah-VL consortium, is currently looking into reusing parts of this web application in a more generic platform, so other projects can also make use of the solutions developed for the Ghent Database of Roman Guilds and Occupation-Based Communities (and vice versa).
In the future, we will be looking into:
- more advanced temporal and spatial visualisations and filters, making it even easier to browse and interpret the data;
- the modeling of uncertainties in dates and other data;
- displaying images related to the data sources using the International Image Interoperability Framework (IIIF);
- exporting the available data as linked open data, enabling the combination of data from GDRG with other datasets available as linked open data (such as Pleiades and Trismegistos).
