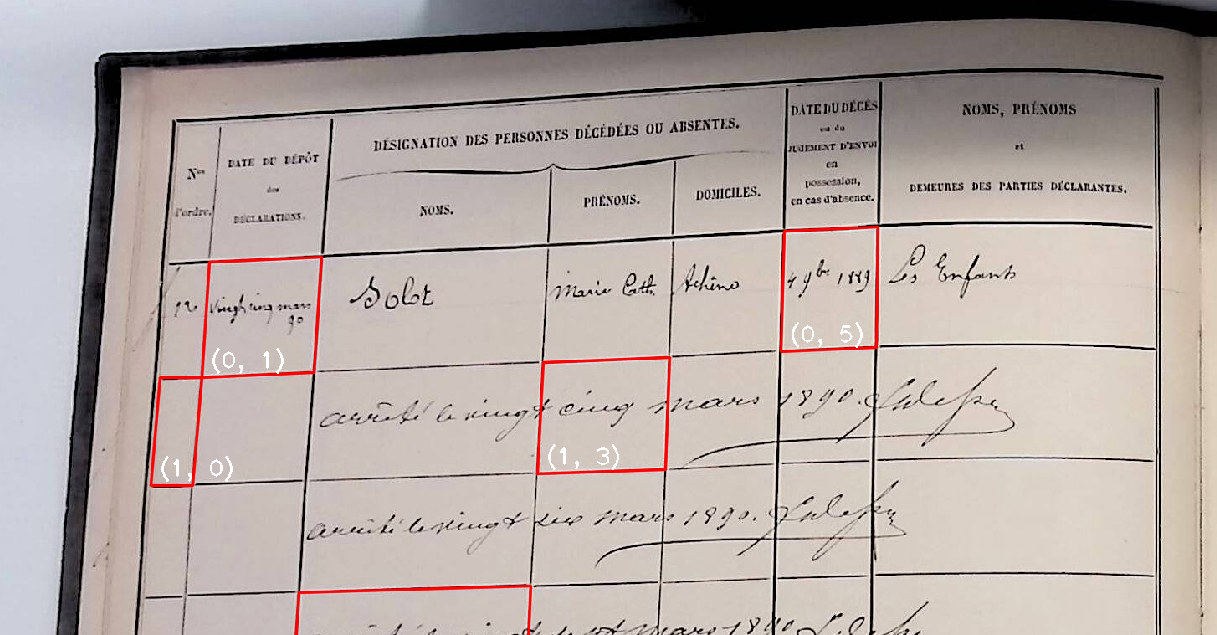
Many historical documents—ranging from administrative records and census forms to scientific logs and weather observations—are preserved in tabular formats. While modern Handwritten Text Recognition (HTR) tools are getting better at transcribing flowing lines of text, they often falter when faced with the rigid structure of tables. These tabular sources are rich in data but difficult to process automatically, especially when handwritten. This creates a significant gap in historical data extraction workflows, where precise segmentation of rows and columns is essential.
Taulu is an open source Python package specifically designed to bridge this gap. Built to complement HTR tools, it focuses on segmenting tabular data from images, enabling researchers to isolate and extract the contents of individual table cells. With a modular architecture and flexible parameters, Taulu can handle a variety of table layouts. By identifying header templates, detecting cell borders, and mapping out the structure of tables, it prepares the data for accurate transcription, a rule based post-processing pipeline and, eventually, analysis. Whether you’re working with 19th-century ledgers or early meteorological logs, Taulu helps to structure the chaos.
Taulu is available on GitHub at https://github.com/GhentCDH/taulu and fits in a growing ecosystem of digital humanities tools aimed at developers. Taulu is developed by Miel Peeters and was partially funded by the Clariah-VL project.